一种新方法加速了 DNA暗物质中基因的映射
人类基因组序列信息在生物医学研究中具有至关重要的意义。然而,由于缺乏基因组中编码基因的详细图谱,这些信息的价值非常有限。基因是决定生物体生物特征的基本生物单位。关于包含编码蛋白质基因的基因组区域的详细信息已经存在,但关于非编码 DNA 区域(也称为 DNA“暗物质”)的信息却滞后。在这里发现了一种不太了解的基因,称为“长链非编码 RNA”(lncRNA),它们是所有基因中数量最多的,并且与多种疾病有关。
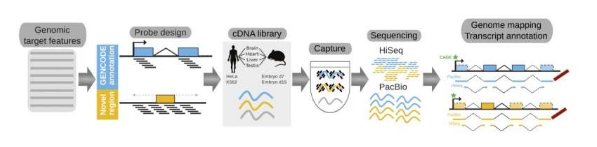
在今天发表在《自然遗传学》杂志上的一篇论文中,由巴塞罗那基因组调控中心 (CRG) 的研究人员领导的国际科学家团队与纽约冷泉港、欣克斯顿威康信托基金会桑格研究所和巴塞罗那 qGenomics 的研究人员合作,对这一主题进行了新的阐释。为了更好地识别、绘制和描述这些“暗物质”基因,他们开发了一种新方法,提高了当前方法的通量和准确性,并将其应用于人类和小鼠。
“我们的 DNA 中有 98% 不编码蛋白质。这些 DNA 区域包含数千个未表征的非蛋白质编码基因,但要完全了解它们的功能及其在疾病中的作用,还有很长的路要走。要实现这一目标,需要完整的基因图谱。我们的方法代表了朝这个方向迈出的重要一步,”CRG 校友、现任伯尔尼大学首席研究员、本论文共同负责人 Rory Johnson 解释道。
这种新方法名为 RNA Capture Long Seq (CLS),其主要特点是它专注于基因组的非编码区域,这些区域使用最先进的测序技术进行扩增和分析。“通过这种方式,我们可以绘制出人类和小鼠中 3,500 种长链非编码 RNA 的详细图谱(约占迄今为止已知的所有 RNA 的 20%)。因此,我们描述了长链非编码 RNA 的基因组特征,以更好地了解这些基因的工作原理,”共同第一作者、CRG 研究人员 Julien Lagarde 和 Barbara Uszczynska 表示。
免责声明:本答案或内容为用户上传,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。 如遇侵权请及时联系本站删除。